
2023-06-05 (MON) 학습정리
#Hadoop #Hive #Zeppelin #Spark
1. Spark 정의
데이터 분석 작업의 개발을 단순화하여 효율성을 높이는 오픈소스 프레임워크
Spark SQL, 실시간 데이터 처리를 지원하는 Spark Streaming, ML 기법을 지원하는 Spark MLib 등의 라이브러리 지원
2. Spark 개요
2-1. spark 설치 (with. docker)
8080 port는 중복되어 18080으로 변경 후 설치 진행함
docker run -p 18080:8080 --name zeppelin apache/zeppelin:0.10.0
2-2. zeppelin notebook
- 파일 업로드 및 이동
docker cp 로컬경로/파일명 zeppelin:/opt/zeppelin # local 파일 → 컨테이너 내부 파일 복사
docker exec -it zeppelin bash # 컨테이너의 bash shell 연결
$ mkdir -p seoul/parquet # 폴더 만들기
$ mv 파일명 seoul/parguet # 해당 폴더로 파일 이동- note book 생성
'http://localhost:18080' 으로 접속 - 상단 'Notebook - Create new note' - 임의의 note name 지정 후 create
- notebook 사용하기
%spark.pyspark
df = spark.read.parquet('/opt/zeppelin/seoul/parquet/*') #parquet 파일 read
df.createOrReplaceTempView("temp_tb") #table 생성%spark.sql
SELECT * FROM temp_tb limit 10;
- 활용 예시
GROUP BY로 가져오면 자체 기능으로 차트 시각화도 가능

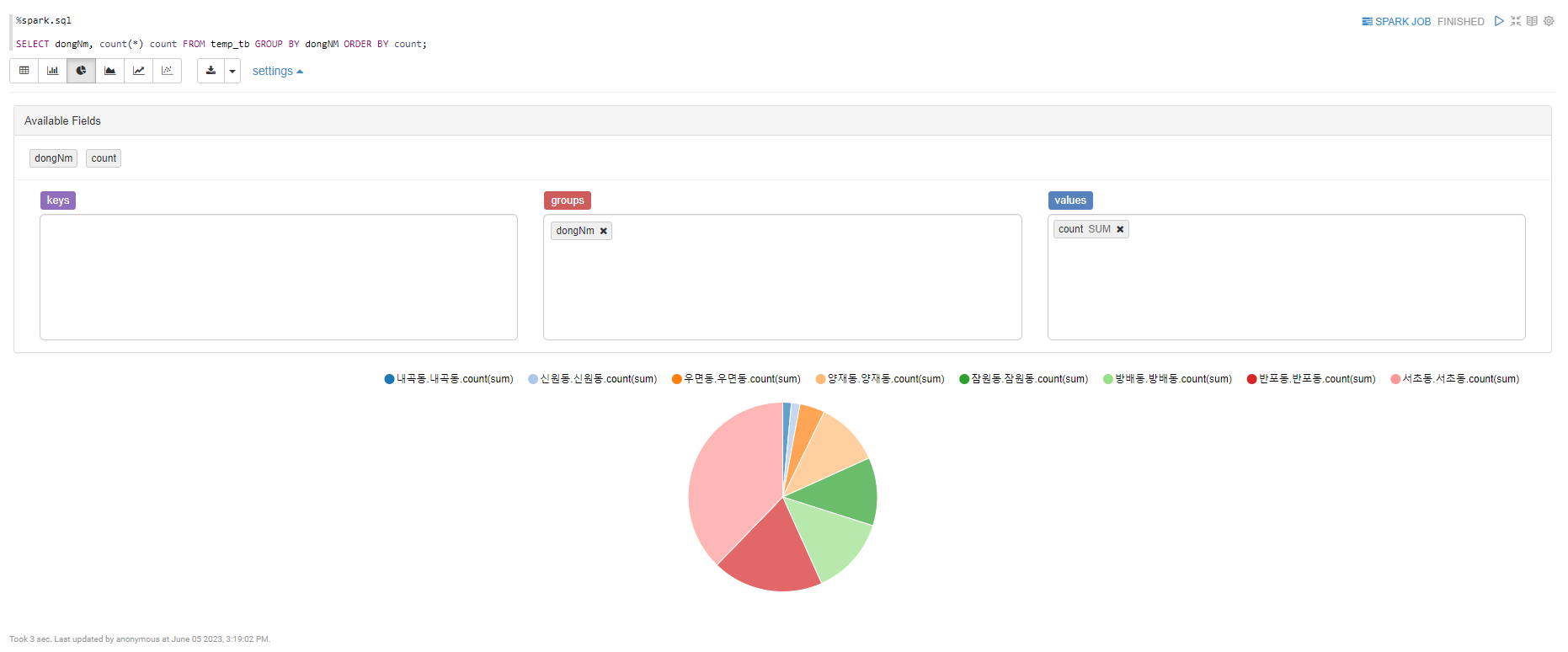
'📊 Data > Engineering' 카테고리의 다른 글
| [Airflow] Airflow의 Python Operator / Hive Operator 사용하기 (0) | 2023.06.09 |
|---|---|
| [Sqoop] Sqoop 설치 및 개요 (0) | 2023.06.08 |
| [HIVE] Airflow / Hive를 이용한 데이터 처리 (0) | 2023.06.02 |
| [Hive] Hive 설치 및 개요 (0) | 2023.05.31 |
| [Hadoop] Hadoop 설치 및 개요 (0) | 2023.05.30 |